前回の雑な整理で、新しい "S3 Glacier Deep Archive " は S3 のストレージクラスとして提供されているので、S3 の API でバックアップ等の操作を行うものだとわかり、HBS3 でも S3 の一員としてバックアップジョブをしているのではないかという想定まで辿り着きました。今回は実際に HBS3 でどうやって "S3 Glacier Deep Archive" へのバックアップジョブを設定するか確認し、簡単なテストを行ってみます。
なお、大切なことではありますが以下のポイントには細かく言及しません。
AWS 関連の基本的な設定(アカウント作成、IAM設定等):これは一度設定してしまえばバックアップのつど再設定するものではなく既存の設定の再利用となります。5,6年前にちょっと S3 を勉強して最初の設定を行ったのですが、今となっては私がそれを再度丁寧に説明するほどしっかり覚えていないことと、分かりやすい解説情報は当時からネット上にいくらでもあることからここではこれらの設定は割愛します。今回の範囲で入力が必須なのは、アクセスキー、シークレットアクセスキーは事前設定したものを利用しています。
HBS3 入力設定項目:バックアップなりリストアするのにどのような設定項目が必要なのかを事前に知ることは大切なことです。しかし今回はポイントとなるいくつかの項目は記事でご紹介しますが、全体としては別途動画にしてどのような設定項目があるのかお見せしたいと思います。記事中に細かい設定を記載するのも煩雑なので。
テストの準備
テストデータ
このテストで 1TB 弱のデータをリストアして一万円を超えるコストが発生してしまったので、少しケチケチでテストしてみようと思います。

テスト方法
NAS 上に、"GlacierTestData" ディレクトリを準備し、このディレクトリをバックアップ対象としたジョブを準備する。
Day1, Day2, Day3 のそれぞれのディレクトリにはそれぞれの日に 1GB 程度のデータを追加していき、毎日データ追加後にバックアップジョブを実行する。(今回はここまでをご紹介します。)
Day4 に合計 3GB 程度となった "GlacierTestData" ディレクトリをリストアしてみる。(これは次回ご紹介します。)
確認事項
思いつくままに、だいたいこんなレベルは確認しておきたいな、と思うものを書き出しました。
コスト
コストに関しては、扱うデータ量が少ないので実測できるほどのコストが発生するか分かりませんのであとで AWS コンソールから確認する程度にしようと思います。
バックアップ時間
- リストア時に「取り出し」時間がかかる Glacier ですが、バックアップ取得時にはさっさとバックアップが完了することは確認しておきたい。
差分バックアップ
差分のデータだけバックアップされていることを何らかの方法で確認したい.
リストア時 (Day4) に全てのファイルが確実にリストアできていること。
リストア(取り出しの設定)
バックアップ済みのデータをリストアするためには、S3 Glacier ではダウンロードする前に Vault (バケット)からデータを「取り出す」というステップが設定され、その処理時間が 3段階ありそれぞれコストが異なります。
「迅速」> 「標準」> 「大容量」
詳細は S3 料金ページを確認いただきたいのですが、S3 Glacier は上記 3段階、S3 Glacier Deep Archive は標準と大容量の 2段階の設定があり、早いほどコストがかかる設定となっています。
旧 Glacier のリストアテストでは大金を散財してしまったので、ケチケチで一番安いけれども一番待たされる、という「大容量」で試したいと思います。
(おまけ) ブラウザからの操作
もともと S3 で扱うファイルはブラウザから操作できます(アップロードやダウンロードも)。
旧 Glacier ではサーバーの Vault にあげてしまったデータはダウンロードしない限り内容を確認できなかったのですが、S3 と同じ扱いができるかもしれません。
QNAP HBS3 でバックアップジョブの準備
ジョブの設定に関しては動画を準備しましたので流れとしてはそれを参照ください。ここではポイントとなる (a) ストレージクラスの設定、(b) バケットとリージョンの設定だけ書いておこうと思います。
動画はこちらを参照ください。
動画で紹介しているジョブの設定はこのテスト用の設定ではなく大切な写真データのバックアップ用ジョブ設定です。この記事で紹介しているディレクトリ等の情報が異なることはご容赦ください。
QNAP のバックアップの統合ソリューションアプリである HBS3 でも 2019/12/06 のリリースで deep archive のサポートが記載されていますので、HBS3 から deep archive を利用したバックアップができるはずです。

(a) ストレージクラスの設定: "Amazon Glacier" を選択しても "deep archive" 関連のメニューが見当たらない
ところが今までのように "Amazon Glacier" を保存先に選択して先に進んでも今までと同様の Glacier の指定項目しか表示されず、今回の最大の目的である "deep archive" といった文言はどこにも見当たりません。

そうなんです。HBS3 で保存先として "Amazon Glacier" を選択してもダメなようで、隣の "Amazon S3 & S3 互換" という日本語が今ひとつわからない方で進めなくてはならなかったようです。

(b) バケットとリージョンの設定
いくつか混乱する表示が AWS 側も HBS3 側も出てきますので覚えていたら後でまとめておきたいと思いますが、旧 Glacier では "Vault" という名称の格納庫を設定してそこにバックアップを取得しますが、ここではバケット (Backet) という S3 標準の名称の格納場所を指定します。本当は今回のテスト用に新しいバケットを作成するつもりでしたが、HBS3 の画面を行き来しているうちに過去にテスト用に作成した "test20161126" というバケットを指定したままジョブを実行してしまいました。
しかし皆さんが初めて S3 にバックアップするにあたってはここでバケットを新規に作成する必要があります。

上記の画像は動画の一部ですが、新規バケット作成にあたってバケット名(ここでは "gda-pro5300")と地域名(ここでは "US East (N. Virginia)")を指定する必要があります。どこのリージョン(地域)のデータセンターを使うか、という指定なのですが、個人情報たんまりで日本から出したくないとか、コストを優先して安いリージョンにしようとかで選べば良いでしょう。この図ではコスト優先で一番ストレージコストの安い北米リージョンを選択しています。
ここは全くの余談なのですが、今回の目玉である "Glacier Deep Archive" はちゃんと S3 のストレージクラスとして選択できました。
ここで若干私の頭の中にモヤモヤが残っていますが、一つの S3 バケットの中に複数の異なるストレージクラスのオブジェクトをバックアップできる、ということなのですね。バケット作成時の 2016年に少なくとも "Glacier Deep Archive" というストレージクラスはありませんでしたから。きっとちゃんと S3 を勉強すれば「ストレージクラス」はバケットの属性ではなくそこに格納されるオブジェクトの属性と書いてありそうです。
バックアップジョブの実行結果
HBS3 での確認
さて毎日データを追加してはバックアップジョブを実行するということを繰り返して、その結果はサマリーとしては下図 HBS3 のジョブ実行結果をご覧ください。

3 回目の処理ファイルが多いのは気まぐれで多くしたこと、4回目の実行で処理済みファイルが 0 なのは新規ディレクトリだけ作成してそこにはファイルを置かなかったためです。またここの表示されているファイル数にはバックアップ対象のディレクトリ自体は数に含まれていません。
処理時間としては、1回目:42秒、2回目:32秒、3回目:1分14秒でした。
ジョブの詳細結果は 3回目だけスクショを掲載しておきます。

AWS コンソールからの確認 (S3)
やはり、AWS コンソールから(ブラウザ上で)バックアップされたファイル単位で存在を確認することができました。旧 Glacier だとバックアップジョブは成功したと結果はわかるのですが、ファイル単位で本当バックアップされたかを確認したいと思ってもできないことだったので、これはバックアップする人にとってはありがたいことです。
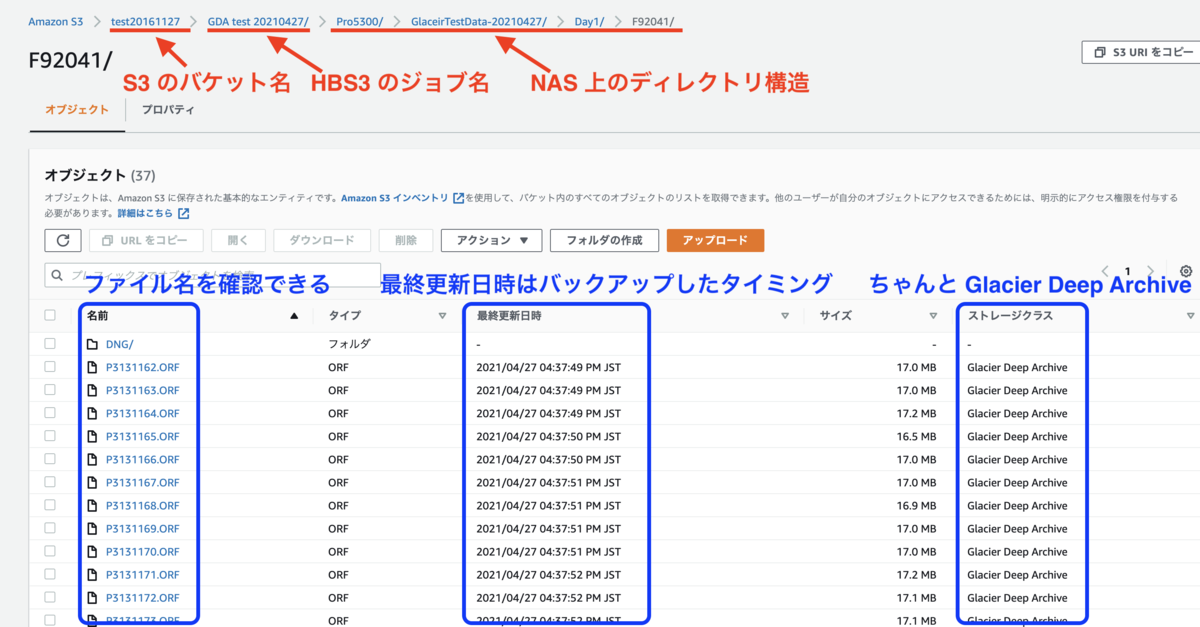
ちなみに HBS3 で指定したバックアップ対象のディレクトリは "GlacierTesData-20210427" なのですが、アップロードされたディレクトリ構造は NAS 上のルートディレクトリ (Pro5300) から表示されていました。
AWS コンソールからの確認 (コスト)
 Glacier, S3 ともテスト実施期間 (04/24-30) はそれ以前とコストに変化は見られませんでした。これは想像するに、今回のテストでは Glacier ではなく S3 にコストがチャージされるはずなのですが、小数点 2桁以下なので表示されないのだと思います(さすがに今となっては無料枠の利用はないと思いますので)。
ちなみに Glacier で毎日 $0.22 チャージされているのは旧 Glacier へのバックアップ分でこれが 1ヶ月で約 $7 になっているので早く削除しないともったいないです‥
Glacier, S3 ともテスト実施期間 (04/24-30) はそれ以前とコストに変化は見られませんでした。これは想像するに、今回のテストでは Glacier ではなく S3 にコストがチャージされるはずなのですが、小数点 2桁以下なので表示されないのだと思います(さすがに今となっては無料枠の利用はないと思いますので)。
ちなみに Glacier で毎日 $0.22 チャージされているのは旧 Glacier へのバックアップ分でこれが 1ヶ月で約 $7 になっているので早く削除しないともったいないです‥
ということで、次回はリストアのジョブを準備して実行してみたいと思います。